
やっと分類器を試します
先ほど学習を完了させました(引っ張ってごめんなさい)。 最後に学習結果を使って画像の分類を行ってみます。
その1を見ていない人はぜひご覧ください。
Caffeを使って自分で作ったデータセットを学習させる(少女時代編)その1
実行する前に手直し
結構前から言われていて現在(2015.9.28)の時点のCaffeの最新コミットでも修正されてないのですが、以下のようなエラーがでるときがあります。
1 2 3 4 5 6 7 | |
このエラーを直します。caffe/python/caffe/io.py(の254行目にかけて)を編集します。
1 2 | |
これを
1 2 3 4 5 6 7 | |
変更。これで今のところエラーはでなくなるので良しとします。
いよいよ少女時代のメンバークラスタリング
snsd_classifyのレポジトリにPythonのスクリプトがあります。
このスクリプトを実行するためにはOpenCVが必要です。
あらかじめインストールしておいてください。
1 2 | |
src.jpgはパスさえ間違えていなければどこに置いておいても構いません。
読み込みが成功すると、OpenCVのウィンドウが出現し、入力画像の顔のクラスタリングを行ってくれます。
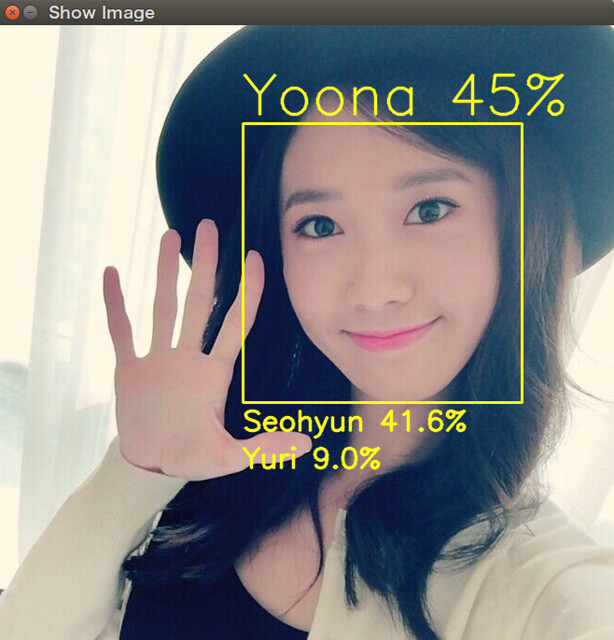
分類結果に満足できればsキーを押してください、/snsd_classify/success_imgに実行日時時間で名前付けされた画像ファイルが生成されていると思います。
保存したくない場合は、sキー以外のキーを押してください。ウィンドウが閉じて、プログラムが終了します。
それにしてもユナがInstagramを始めてくれてよかったですね!!
おわりに
やっとの思いで、少女時代のメンバーのクラスタリングができました。
何よりデータセットを作成するのが大変でした。
少女時代のメンバーのクラスタリングに関しては各メンバーに1000〜2500枚、負例約3500枚を用意しましたが、これでも少ない方です。
ほんとはもっと用意すると良い結果が得られると思います。ディープラーニングはデータセットの量と質に大きく依存します。
今回用いたデータセットの年代は主に2011年から2013年までの写真が主でした(筆者が好きすぎて画像を漁りまくっていた年代)。 この偏りのせいか、正直ちょくちょく間違えます。ユリ、ユナ、ソヒョンのあたりは特に。 人間でもはじめにぶち当たる判別困難な3人ですね。
また売り出すCDのテーマによって激しく髪色、メイクが変わるため,データが偏っていると識別が非常に難しくなります。
したがってデータセットを作るときにはまんべんなく年代から抽出して作成し、学習させたほうがいいのかもしれません。
この記事を書く際にはできるだけ最近アップされた画像を使用しています。
当然学習には入っていないころのデータですが、まあまあの精度で当ててくれます。
こういったところがDeep Learningの面白いところですね。
例え間違えていても、見当はずれな間違いではなく「あーこれは人間も間違えるかな」っていうことも多いので、実に人間らしいところがあります。
インストールが一番の関門だったりしますが、Caffeを利用して最近大流行りのDeep Learningの最新の技術に触れてみるのもいいかもしれません。
もしエラーが出て本記事で登場したプログラムが動かない等の問題が起こりましたら、コメントをください。
長編のブログ記事になりましたが、最後まで閲覧してくださりありがとうございました。
