少女時代の顔を自動で切り出す
本日は前回に記事でインストールしたCaffeを使ってDeep Learningを行うためのデータセット作成の回です。 PythonとOpenCVを使って大量の写真から顔を切り出すスクリプトを作成したので、よかったらつかってみてください。
環境の確認
Ubuntuで標準でインストールされているPython 2.7.6を使用しています。
またOpenCVを使用しているため、インストールしておいてください。
インストール方法に関しては前回に記事の最後あたりに書いています。
ソースコードをClone
ソースコードはここにあります。 今回は使いませんが、動画から大量に顔写真を切り出すプログラムもこの中においてます。 こちらの方は最近メンテナンスしてないので、もしかしたら動画ファイルによってはうまく動かないかもしれません。
このレポジトリをcloneしてきます。
1
| |
そして処理の進捗を可視化する関係で以下のパッケージをインストールします。
1
| |
元画像の用意
大量に写真を用意します。写真はjpgかpngで用意してください。 フォルダは1つにまとめておく必要がありますが、そのフォルダの中にフォルダを配置して画像を格納しておくのは大丈夫です。 zip等の圧縮形式には対応していません。
少女時代の顔識別をしたいので、今回は大量の少女時代写真を用意しました。
実行
さっそく実行します。
1 2 | |
引数であるsrcは大量の元写真データのフォルダを指定して、outputは切り出した画像が保存される場所を指定します。
途中経過の様子はこんな感じです。
1 2 3 4 5 6 | |
最後にComplete !と表示されたら正常に完了しています。
地獄のフォルダ仕分け
先ほど切り出した顔写真を仕分けする作業を行います。 この作業が地獄で、顔を検出したといっても誤りも多く、手動で選定しなけれなりません。
仕分け先のフォルダとそのあとの学習を行うためのレポジトリはここにあります。
ただし、これは少女時代の顔を識別するためだけに作ったレポジトリですから、目的に応じて使用してください。
このレポジトリをcloneしてきます。cloneしてくる場所はcaffeの中です。
1 2 | |
cloneできたらデータセットの仕分け作業はcaffe/examples/snsd_classify/snsd_dataの中で行います。
このディレクトリには0,1,2,3...とフォルダがあると思います。これはそれぞれのメンバーに仕分けるためフォルダです。数字とメンバーの関係は以下の通りです。
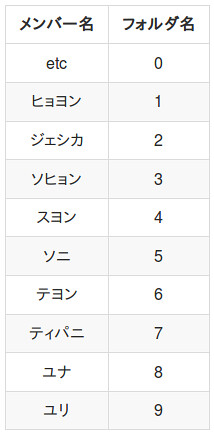
これに従って、ひたすら仕分けします。
画像の正規化
仕分けした画像に対して正規化処理を施します。これを行ったほうが学習精度が向上するとかしないとか。 これを行うと一生懸命仕分けした画像データが正規化されて上書きされてしまうので、綺麗な状態で一度フォルダをバックアップしておくといいです。
各フォルダに移動してこのコマンドを入力します。
1
| |
LevelDB形式に変換
caffe/examples/snsd_classify/snsd_dataにbuild_leveldb.pyがあると思います。これをエディタで開いて43行目を自分のcaffeがインストールされている場所に合わせて変更してください。
1
| |
あと18行目のTHUMBNAIL_SIZE = 64と定義しています。snsd_classifyのレポジトリでは学習を行う際にデータセットの画像サイズを64にしています。
少女時代の顔検出をしたいひとであれば、気にせずこのレポジトリの学習モデルを使っていただければいいのですが、cifar10のモデルを使用する場合などはサイズは32で定義してありますので使用する学習モデルに合わせて変更してください。
修正が行えたら、スクリプトを実行します。
1
| |
成功したらsnsd_classifyにsnsd_cifar10_test_leveldb、snsd_cifar10_train_leveldbというフォルダができていると思います。
これでデータセットの用意は終了です。
おわりに
私も少女時代のメンバー9人+負例のetc含めて2万枚程度、手作業で仕分けしました。 画像の数が多すぎてファイラーがハングアップしたり、なかなか大変な作業です。 しかしデータセットが多いほど学習の精度は向上しますから、頑張って自分好みのデータセットを作成してみてください。
次回はついにCaffeを使って学習を行います!