
独自のデータセットで学習、分類
前回のディープラーニング記事から随分時間が経ってしまいました。
もし楽しみにしていた人がいたら大変お待たせしました。
いよいよ前回で作成したデータセットを学習、分類器を作成してみるの回です。
できるだけ丁寧に書くつもりなのでよかったら見ていってください。
前回までのあらすじ
時間が経っているので前回までのおさらいをしておきます。
今日書く方法は、この手順に沿って行っていますので一応目を通しておいていただくと再現性が高くなります。
GPUによる並列計算の準備
もしNVIDIAのグラボを使っているなら、導入してみましょうっていう記事です。
Ubuntu 14.04にCUDA 7.0とcuDNNを導入する
Caffeのインストール
この回でCaffeをインストールしました。
UbuntuにCaffeをインストールする
データセット作り
ここで少女時代のメンバーの顔写真データを大量に作りました。 分別は地獄です。
Caffeを使ってDeep Learningするためのデータセット作り
本日の作業はここから
前回のデータセット作りで下のレポジトリをcaffe/examples/にcloneしてくれたと思います。
学習を行うために本レポジトリにcdしておきます。
1
| |
前回の記事での作業でsnsd_cifar10_test_leveldbとsnsd_cifar10_train_leveldbがsnsd_classifyのディレクリにできていることを確認した後、以下のコマンドを実行します。
ただし実行する前にsnsd_cifar10_full_solver.prototxtの最後の行をCPUかGPUを環境に応じて変更してください。
1
| |
このスクリプトはただ平均画像(meanファイル)の作成、そして学習の実行を行っているだけです。このスクリプトが上手く動作しない場合はスクリプトの内容を一行ずつ実行してみてください。
学習が完了するとsnsd_classifyのディレクリに以下のファイルが生成されます。
snsd_cifar10_full_150717_iter_60000.caffemodelsnsd_cifar10_full_150717_iter_60000.solverstate
ここまでできると学習は完了です。
学習の結果
学習の結果を示します。いろいろ試行錯誤した結果、データセットの数が少ないのか普通にCifar10で用いられている学習モデルをそのまま使った場合、訓練データとテストデータに関する学習の精度の乖離が見られました。
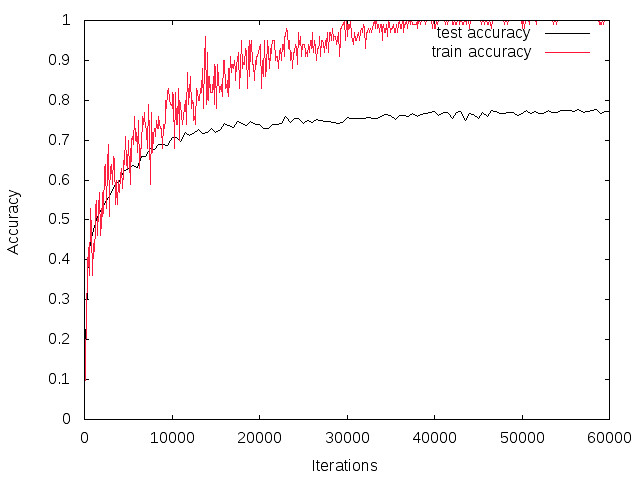
Cifar10のモデルを使用した場合
本レポジトリをそのままクローンした場合、この学習モデルは使っていませんが、レポジトリのブランチを切り替えると試せます。
Dropoutを試してみる
Cifar10の学習のモデルではあまりよい結果が得られなかったので、データをランダムにクロップして学習につかったり、画像を左右反転させたり、データの水増しを行いました。 あとDropoutと呼ばれるブロックを追加しています。 このCifar10の学習モデルを改造したもので学習を行っています。
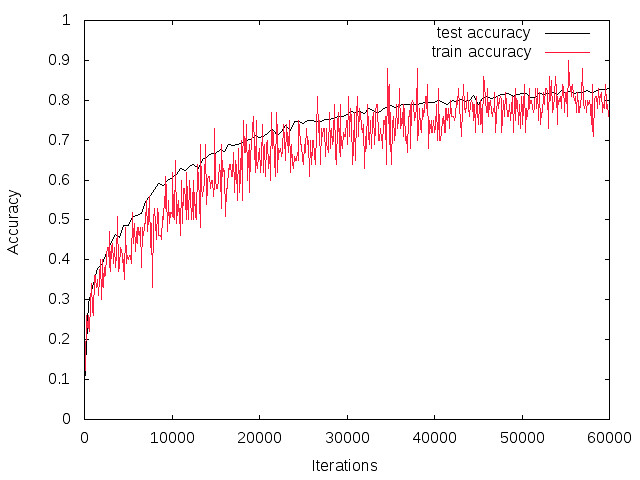
上のプロット結果のように何も対策をしていない結果よりも良い結果が得られています。
最終的にはテストデータに関する精度も82%とCifar10のモデルを使用したときよりも精度が向上しています!
学習データのプロット方法
ちなみに学習結果のプロット方法はここのサイトが詳しいですよ。
CaffeでMNISTを学習した経過をプロットしてみた
このサイトの方法をそのまま使っても訓練データの結果しか出力されません。
テストデータに関しての結果もプロットするようにしたスクリプトがあるので使ってみてください。
クローンしてきたレポジトリのsnsd_classify/plot/parse_log_mod.shを/caffe/tools/extra/にコピーして使用し、引用ブログにあるように作業を行って
1
| |
これの代わりに
1
| |
としてください。出力結果をそれぞれdropout.log.testとdropout.log.trainにリネームし、snsd_classify/plot/dropoutにコピーしてください。同じファイルがありますが、例として置いているだけなので上書きしてもらって構いません。
1 2 | |
で画像が生成されます。
おわりに??
記事が長くなっているので一旦切ります。 次に分類器にかけてみる話をします。
Caffeを使って自分で作ったデータセットを学習させる(少女時代編)その2